Die Handhabung der Waren in einem Hochregal durch ein Regalbediengerät (RBG) lässt sich als Reinforcement Learning Problem formulieren. Ziel des Prototyps in diesem Beitrag ist es, die grundlegende Funktionsweise eines Regalbediengerätes zu erlenen. Basierend auf diesen Grundlagen können komplexere Szenarien abgebildet werden um effizientere Strategien für bestehende oder zukünftige Hochregallager zu finden.
Einstieg in Reinforcement Learning
Reinforcement Learning baut auf dem Prinzip der Interaktion eines Agenten (Agent) mit einer Umgebung (Environment) auf. Der Agent kann per Aktion (Action) mit der Umgebung interagieren und so Einfluss auf sie nehmen. Der Zustand der Umgebung wird in Form einer Beobachtung (Observation) vom Agenten wahrgenommen. Dadurch entsteht ein Wechsel zwischen Aktion und Beobachtung. Zusätzlich zur Beobachtung enthält der Agent eine Belohnung (Reward) nach jeder Aktion. Ziel des Reinforcement Learning ist es, die Belohnung die ein Agent erhält zu maximieren. Während des Trainings wird das Verhalten des Agenten Schritt für Schritt angepasst um höhere Belohnungen erzielen zu können.
 State Action Graph
State Action Graph
Die Bedienung eines Hochregals als Reinforcement Learning Problem
Environment/Umgebung - Zustand von Hochregal, Regalbediengerät und Bedarf
Für den Prototypen werden das Regal und der Bedarf möglichst einfach dargestellt. Insbesondere der Bedarf kann auf komplexe Arten individuell formuliert werden, je nach Beschaffenheit des Prozesses in den das Hochregal eingebettet ist.
- Das Hochregal wird als rechteckig mit $w*h$ Plätzen definiert. Ein Platz kann einen Artikel enthalten oder leer sein.
- Ein Platz im Lager wird als Einlagerungspunkt definiert. Dort erscheinen neue Waren wenn der Platz leer ist.
- Im Auslagerungspunkt werden Waren abgelegt um sie aus dem Regal zu entfernen. Über den Auslagerungspunkt werden die Artikel in der Bedarfsliste abgearbeitet.
- Der aktuelle Warenbedarf ist als Liste von Artikeln gegeben. (Eine Alternative wäre z.B. eine Warteschlange mit exakter Reihenfolgenvorgabe)
- Die Position des Regalbediengerät wird durch xy-Koordinaten dargestellt.
- Das RBG kann leer sein oder einen Artikel tragen.
Observation/Beobachtung
Der oben beschriebene Zustand des Hochregallagers muss in Form einer Observation codiert werden, um als Eingabe für den Algorithmus dienen zu können. Hierfür gibt es verschiedene Möglichkeiten. Eine einfache Variante ist es, jede relevante Variable in eine Liste zu schreiben und die komplette Liste als eindimensionale Eingabe zu verwenden. Hierbei würde die zweidimensionale Struktur des Regals umgeformt werden.
Eine Codierungsvariante, die die räumliche Struktur beibehält kann jedoch sinnvoller sein, da dadurch Verfahren verwendet werden können, die räumliche Strukturen nutzen wie z.B. Convolution-Netze. Eine solche Darstellung behält die zweidimensionale Anordnung des Regals bei. In der dritten Dimension (Tiefe bzw. 'Kanäle'/'Channels') können Informationen Codiert werden, wie z.B. Artikeltyp, RBG-Position, Artikelbedarf etc.
 Beispielhafte Codierung eines Regals mit zwei Artikeltypen. 'Kanal' bezieht sich in dieser Grafik auf die Codierung der Informationen ('Channel'), nicht auf ein Kanal eines Kanalregals.
Beispielhafte Codierung eines Regals mit zwei Artikeltypen. 'Kanal' bezieht sich in dieser Grafik auf die Codierung der Informationen ('Channel'), nicht auf ein Kanal eines Kanalregals.
Aktionsraum - Regalbediengerät
- Um die Position zu ändern, kann das Gerät nach oben, unten links und rechts fahren.
- Um mit dem Regal zu interagieren, kann das Regalgerät Ware aufnehmen und ablegen.
- Wenn kein Handlungsbedarf besteht, kann das Gerät warten.
Reward/Belohnung
Die Formulierung der Belohnung ist entscheidend für den Lernerfolg und Sinnhaftigkeit des Verhalten des Agenten. Häufige kleine Belohnungen können dem Lernprozess helfen und ihn somit beschleunigen - geben aber auch Implizit Verhalten vor und müssen daher mit Bedacht gewählt werden. Die wichtigste Belohnung in diesem Szenario ist die Ablage von Waren für die Bedarf besteht. Weitere Hilfsbelohnungen wie z.B. für das Entnehmen von Ware aus dem Einlagerungspunkt und Bewegung von korrekter Ware zum Auslagepunkt können den Lernprozess unterstützen. Negative Belohnungen zu jedem Zeitschritt erzeugen eine Dringlichkeit in der Handlung des Agenten.
Beispielszenario
Es wird ein Beispielszenario geschaffen, um zu prüfen ob der trainierte Agent sinnvolle Aktionen wählt.

- Größe des Regals: Höhe 4, Breite 4
- Es gibt drei verschiedene Warentypen ('1', '2' und '3')
- Wahrscheinlichkeit, dass ein Bedarf entsteht (pro Umgebungsschritt): 10%
- Wahrscheinlichkeit, dass in Einlagerungsbereich neue Ware erscheint: 50%
- Die Wahrscheinlichkeiten dass Bedarf und Nachschub des Warentyps 1,2 oder 3 entsteht hängen vom Bestand des Lagers ab. Je häufiger ein Artikel im Lager ist, desto unwahrscheinlicher der Nachschub.
- Maximale Anzahl an gleichzeitigen Bedarfen: 1
Baseline
Zum Vergleich des gelernten Agenten wird ein regelbasiertes Verfahren als Baseline betrachtet. Das Grundprinzip ist es, Artikel aus dem Einlagerungsplatz auf einen freien Platz mit kleinstem Abstand zum Einlagerungsplatz zu legen. Befindet sich Bedarf im Regal, wird der benötigte Artikel mit dem kleinsten Abstand zum RBG zum Auslagerungsplatz gebracht. Somit sollen möglichst kurze Wege bevorzugt werden.
Pseudocode der Baseline Policy:
# if payload is not empty
# if payload is demand
# goto target and drop
# else (payload is not demand)
# if rack is full
# go to target and drop (free up new space if there is demand, rack is full and only non-demand items in rack)
# else
# goto closest empty slot and drop
# else (payload is empty)
# if demand in rack
# go to demand in rack and pick up
# else (demand not in rack)
# if at source
# pick
# if empty slots left
# go to source
# else (no empty slots left)
# if all demand slots are full
# if no demand in rack
# go to source (go to source to free spawn space for demanded item)
# else (not all demand slots full)
# go to target (for quick delivery at next demand)Ergebnis
In diesem Abschnitt sind verschiedene Ausschnitte des Verhalten eines trainierten Agenten dargestellt.
| Nachschub |
|---|
 |
| Nachschub wird als solcher erkannt und aus dem Einlagerungspunkt genommen um ihn zu verstauen. |
| Verstauen |
|---|
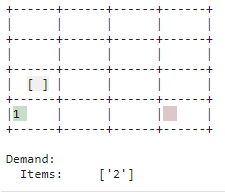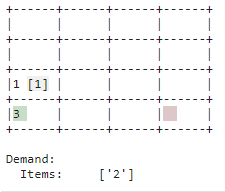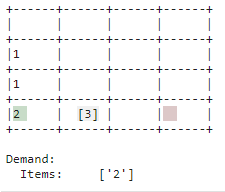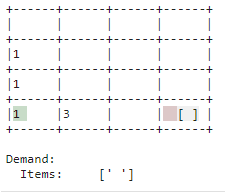 |
| Nachschub, der nicht unmittelbar gebraucht wird, wird abgelegt. Der Lagerplatz wird als solcher verwendet. Somit wird Platz im Einlagerungspunkt für neuen Nachschub geschaffen und es kann schneller auf Bedarf reagiert werden wenn der entsprechende Artikel im Lager ist. |
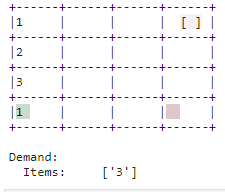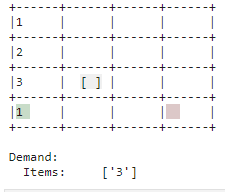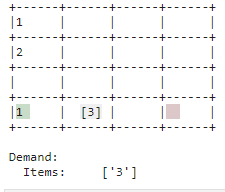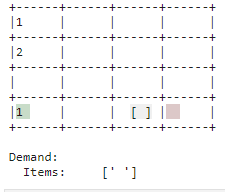
| Bedarf |
|---|
| Der Bedarf wird mit korrekten Gegenständen im Lager assoziiert und via Ablegen des Gegenstands im Auslagerungsbereich nachgekommen. |
 |
| Befüllung |
|---|
| Das Lager wird von links unten befüllt, es werden also kurze Strecken (zum Einlagerungspunkt) bevorzugt. |
 |
Durchsatz
 Die Abbildung zeigt den Durchsatz von jeweils dem RL-Agenten und der Baseline über 1000 Zeitschritte hinweg (je 300 Wiederholungen, geglättet über 100 Samples, 95%-Konfidenzintervall).
Bis ca. Zeitschritt 600 ist der RL-Agent im Mittel besser als die Baseline, danach wiederum die Baseline.
Bereits in diesem simplen Szenario können in kurzer Zeit Strategien entdeckt werden, die eine konkurrenzfähige Alternative für eine starke Baseline darstellen. Mithilfe weiterer Optimierungen können die bestehenden Ansätze noch weiter ausgebaut werden. In komplexeren Szenarien besteht mehr Spielraum für fortgeschrittene Strategien, was wiederum Möglichkeiten für den RL-Agenten entfaltet.
Die Abbildung zeigt den Durchsatz von jeweils dem RL-Agenten und der Baseline über 1000 Zeitschritte hinweg (je 300 Wiederholungen, geglättet über 100 Samples, 95%-Konfidenzintervall).
Bis ca. Zeitschritt 600 ist der RL-Agent im Mittel besser als die Baseline, danach wiederum die Baseline.
Bereits in diesem simplen Szenario können in kurzer Zeit Strategien entdeckt werden, die eine konkurrenzfähige Alternative für eine starke Baseline darstellen. Mithilfe weiterer Optimierungen können die bestehenden Ansätze noch weiter ausgebaut werden. In komplexeren Szenarien besteht mehr Spielraum für fortgeschrittene Strategien, was wiederum Möglichkeiten für den RL-Agenten entfaltet.
Learnings
Beim erstellen einer Umgebung für Reinforcement Learning gibt es verschiedenste Aspekte zu beachten. Zum Beispiel:
- Das Analysieren von Verhalten trainierter Agenten hilft, etwaige Fehler in der Gestaltung der Belohnungen ausfindig zu machen. Solche Fehler äußern sich zum Beispiel in der Wiederholung einer Abfolge von vermeintlich unnützen Aktionen.
- Falls möglich, ist es sinnvoll eine Baseline-Policy zu erstellen um die Güte des Agenten einordnen zu können.
- Das Gestalten einer skalierbaren Welt (Größe und Schwierigkeit) hilft für schnelles Debugging verschiedener RL-Algorithmen.
- Verständnis für die Parameter des Algorithmus und ihre Auswirkungen sind wichtig, um Fehlerfälle gezielt entgegenwirken zu können.
- Eine Hyperparametersuche kann helfen, um robuste Parameter zu finden.
Fazit und Ausblick
Das erleneren der Steuerung eines Regalbediengerät ist eine herausfordernde Aufgabe. Dieser Artikel zeigt, dass mithilfe von Reinforcement Learning die Steuerung eines Regalbediengeräts gelernt werden kann. Das gelernte Verhalten könnte zur Steuerung verwendet werden, oder dazu beitragen, bessere Bewegungs- und Belegungsstrategien für ein gegebenes Szenario zu identifizieren. Der erzielte Durchsatz ist konkurrenzfähig zu einem Regelbasierten Ansatz.
Ein robusterer, praxisorientierterer Ansatz könnte sein anstatt die komplette Steuerung zu lernen, die Auswahl bzw. das Umschalten zwischen etablierten Strategien gegeben der Bedarfs- und Lagersituation zu erlernen um so flexibel reagieren zu können.





