



WHATS IMPORTANT

📍 Google I/O 2021
From May 18-20th, Google held its annual developer conference in Mountain View, featuring numerous technology announcements. This year's conference was very AI-heavy. In this brief, Google AI Lead Laurence Moroney catches you up on the Top 10 Machine Learning developer updates (youtube.com). Our 3 favorites are comprised below.

Laurence Moroney / Google
💬 Google introduced the "Language Model for Dialogue Applications”, LaMDA in short. Unlike most other language models, LaMDA is trained on dialogue, allowing better open-ended conversations. LaMDA is not limited to a human-like perspective for discussions. In the keynote, the tech giant presents how their model can take the perspective of inanimate subjects, such as the planet Pluto. – More in the Google Blog (blog.google).

A conversation with LaMDA posing as the Planet Pluto / Google
🧍 A new version of the People + AI Guidebook was published. According to Google AI Lead Laurence Moroney, this update is "designed to help you put best practices and guidance for people-centric AI into practice with a lot of new resources including code design patterns and a whole lot more." (pair.withgoogle.com).
🤖 Google MUM, short for MultiTask Unified Model, is a novel language model set to drastically improve Google Search results. It is based on the Transformer architecture but "1000x more powerful than BERT". MUM is trained across 75 languages and many different tasks at once and it is multimodal, so it understands text and images (and soon video and audio).

Similar to when BERT was introduced, the company indicates that the new MUM algorithm will not be published until the company has rigorously tested the system for quality and biases (blog.google).
Watch a summary of the Google I/O developer conference from The Verge here (16 minutes on youtube.com).
THINGS WE FOUND WORTH SHARING
👩💻 Code & Tools – Data Cleaning takes time! According to a survey conducted by Anaconda, 25% of a Data Scientist's time goes into cleaning data. MIT’s Probabilistic Computing Project aims to simplify and automate the development of AI applications. They have just introduced PClean, a tool that automatically cleans messy data tables – Read the announcement on news.mit.edu and try out PClean on GitHub. (github.com)
MIT Technology Review
📰 News – The Developer Community Stack Overflow was sold to Dutch/South African tech holding Prosus for 1.8 billion USD. While no changes have been announced to the platform yet, deeper integration into Prosus's other investments - such as Udemy and Codecademy - seems more likely than ever. Prosus is also the largest shareholder in Chinese internet giant Tencent. (wsj.com)

Stack Overflow
📄 Paper – A new computer vision model called MLP-Mixer was proposed by researchers from Google Brain. The paper "MLP-Mixer: An all-MLP Architecture for Vision" (arXiv), introduces a model that does not use convolutions or attention but consists of Multi-layer Perceptrons only. Still, it achieves near state-of-the-art (SOTA) results.
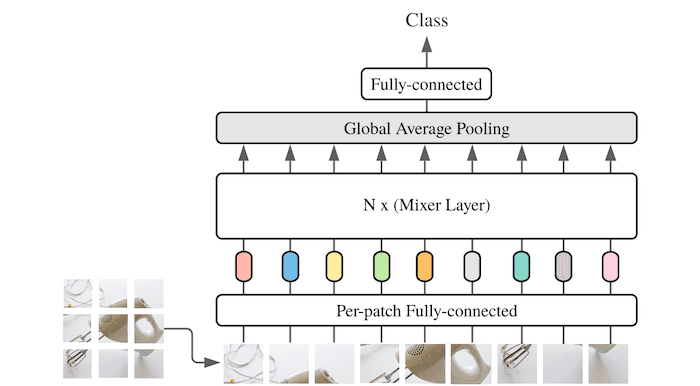
Google Brain / arXiv
✏️ Read a short summary on TWD (towardsdataschience.com) or watch a thorough paper discussion by Yannic Kilcher (youtube.com).
👩💻 The official Code implementation is available here (github.com), and an unofficial PyTorch Implementation was published by GitHub user rishikksh20 (github.com).
👯 At the same time, Facebook AI was working on ResMLP, which follows the same idea. They published their results three days later in "ResMLP: Feedforward networks for image classification with data-efficient training" (arXiv), but MLP-Mixer stole the limelight.
👩💻 Code & Tools – LinkedIn open-sourced Greykite, a strong library for time series forecasting. The library is available on GitHub (github.com).

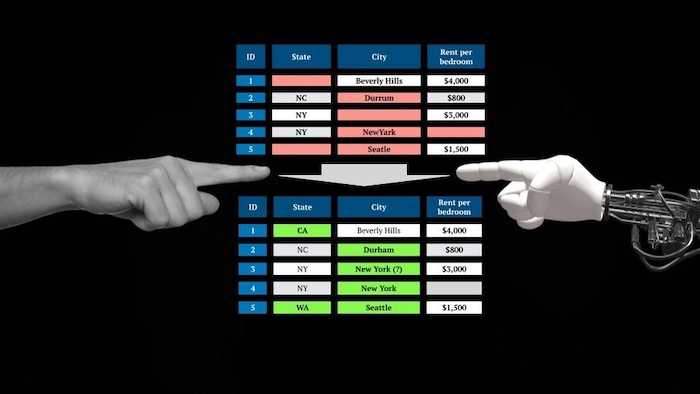
💡 Use Case – Last year, we reported how Microsoft acquired an exclusive license to commercialize OpenAI's GPT-3 language model. Now, Microsoft has put it into its first use case. A new tool in PowerApps can turn natural language into code. While it is currently limited to formulas in Microsoft Power FX, mainly used for database queries, it leaves hope for more to come. (theverge.com)
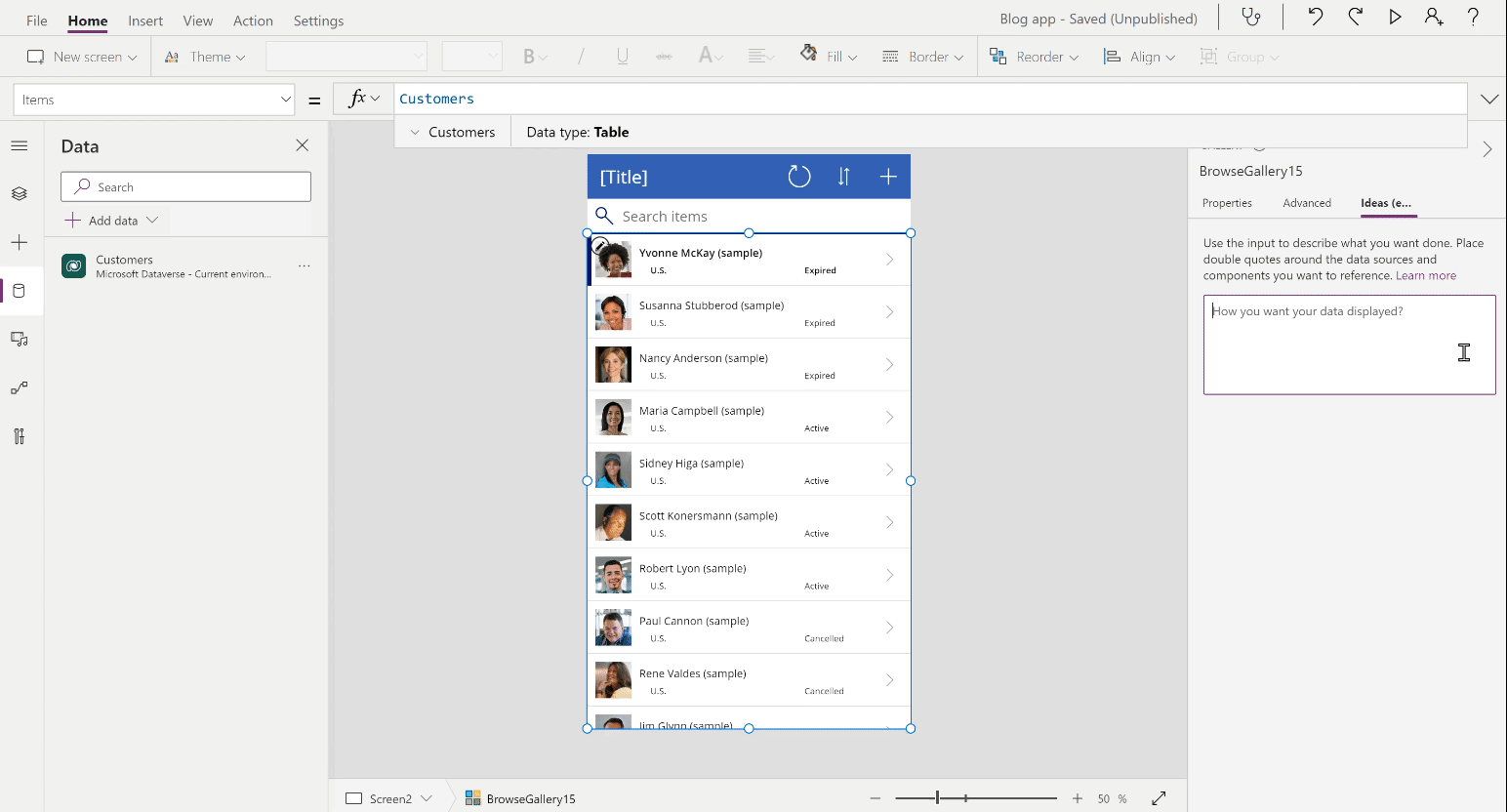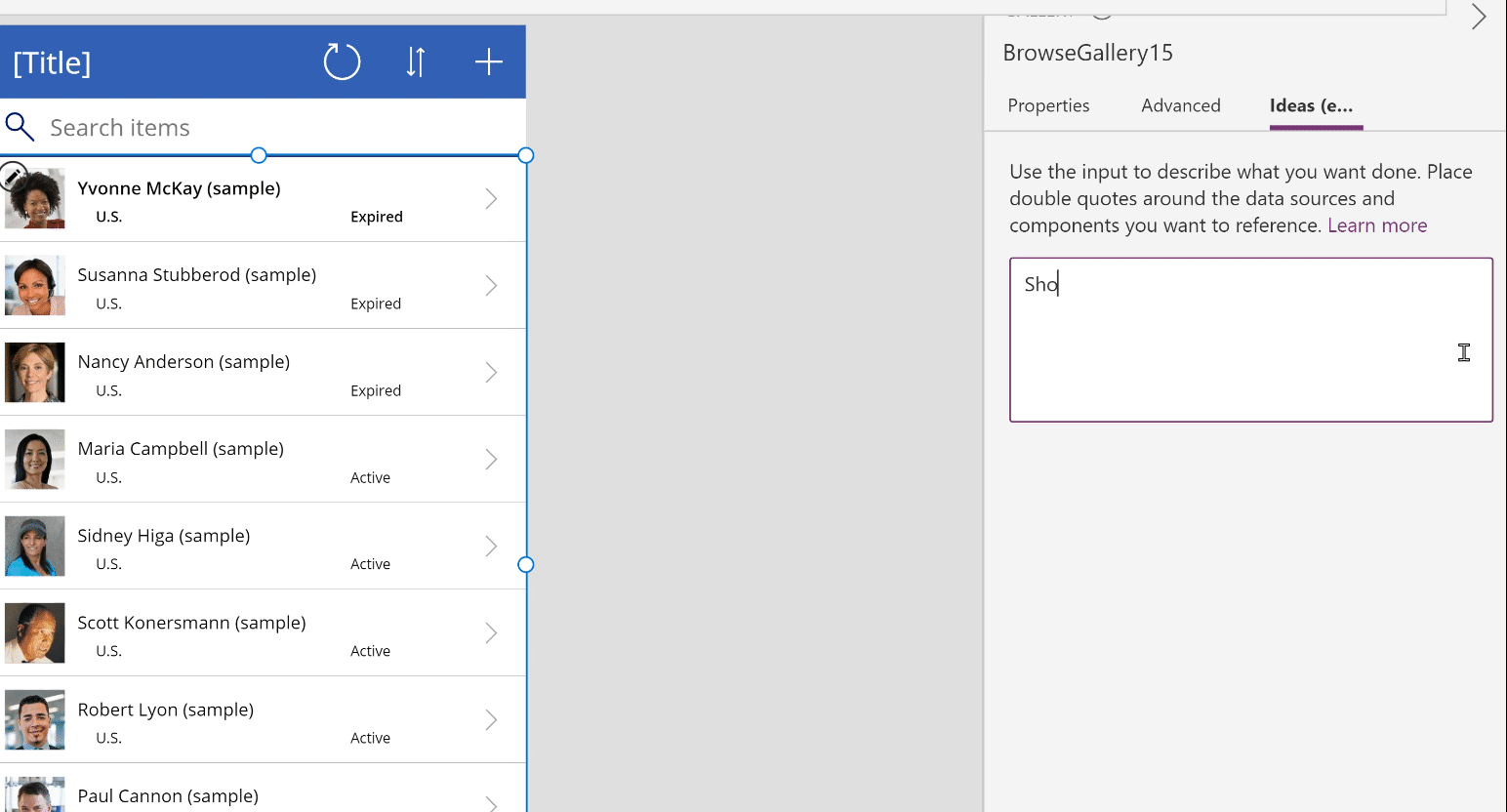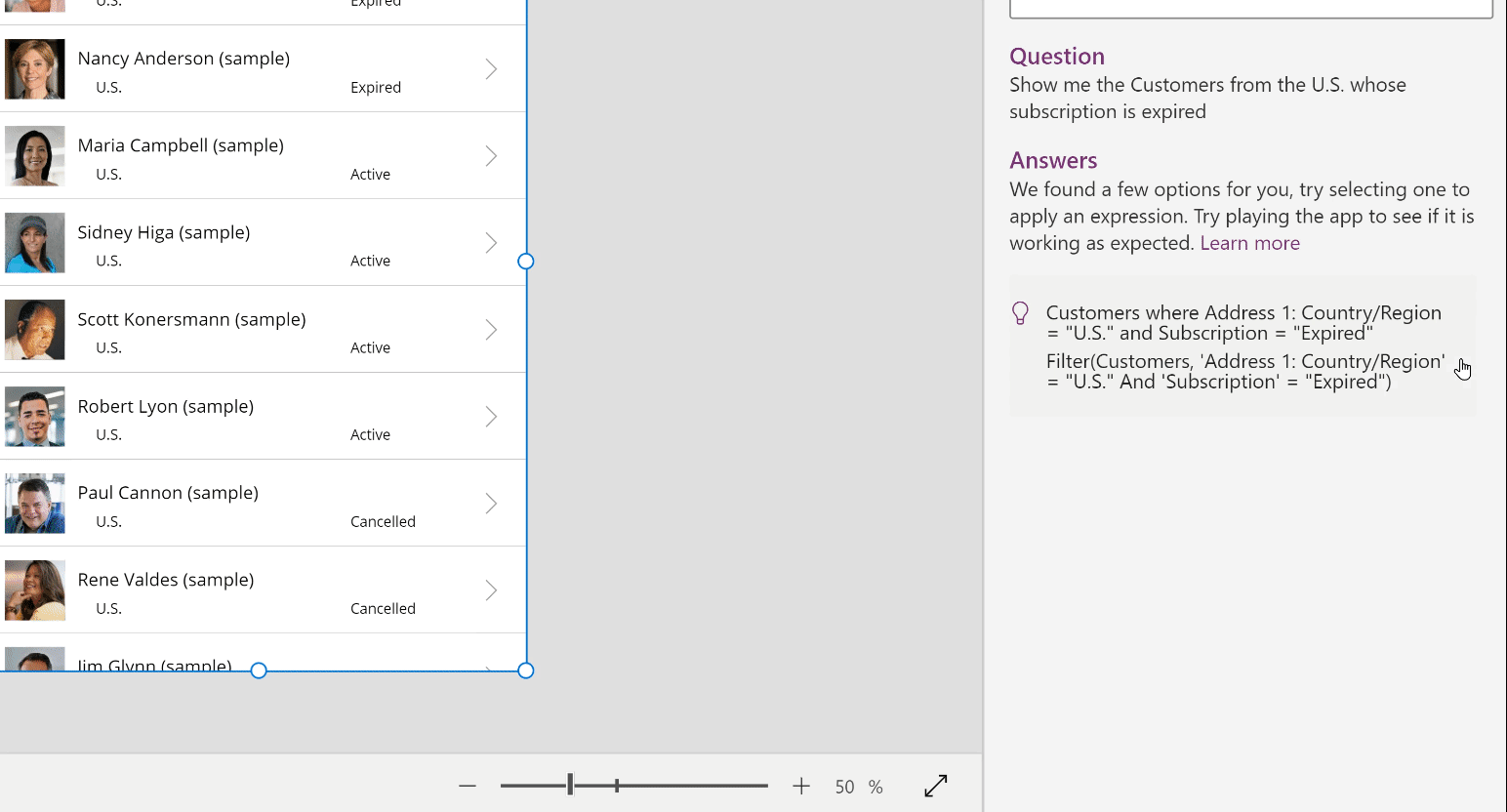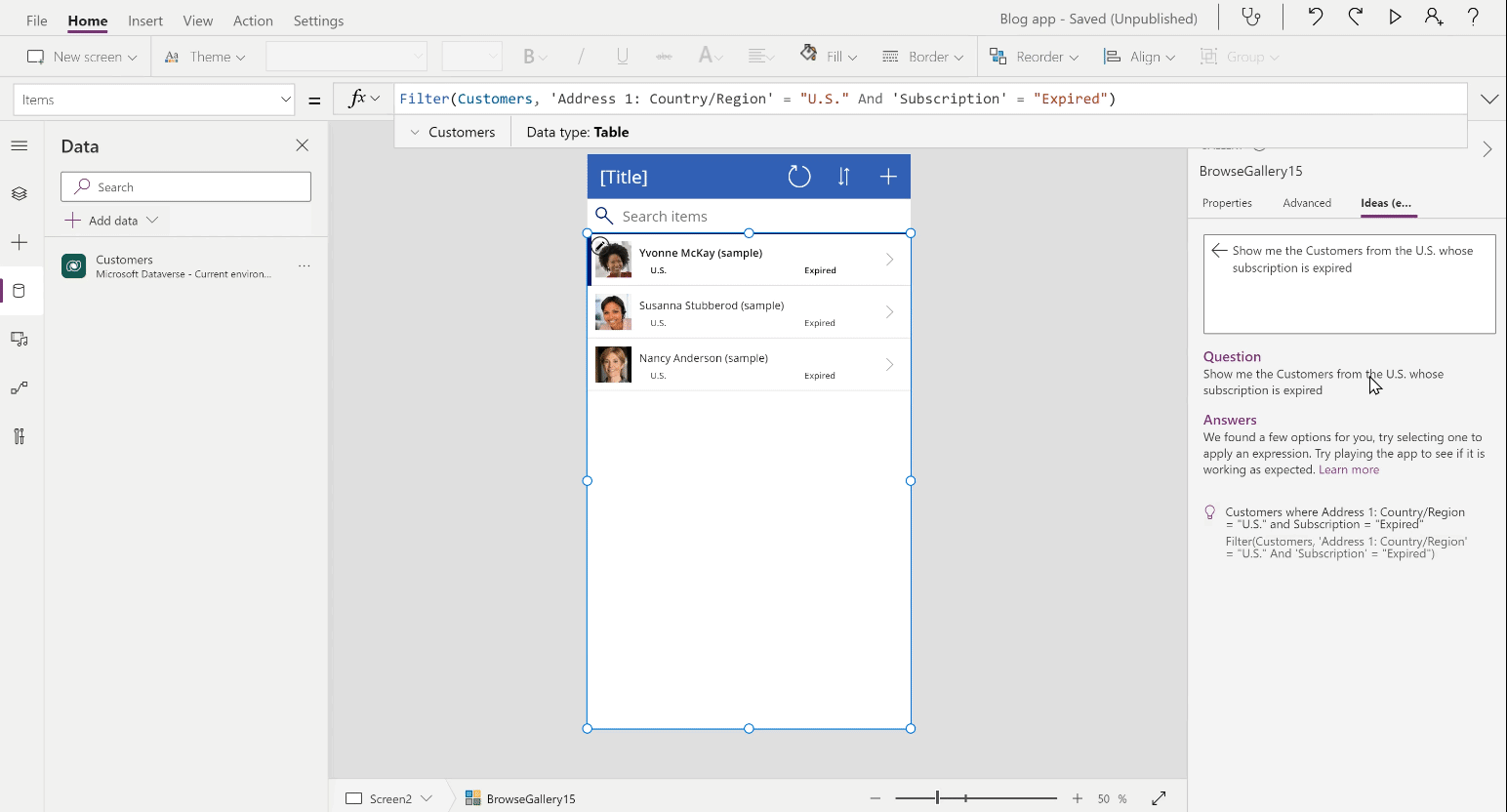
Microsoft
📄 Paper – Teaching AI how to forget at scale with Expire-Span: Researchers from Facebook AI tried to mimic the way humans retain memories in their recent paper "Not All Memories are Created Equal: Learning to Forget by Expiring" (arXiv).
"Our brains naturally make room for important knowledge by providing easy access for recollection rather than becoming overwhelmed with every detail. Similarly, Expire-Span helps AI keep data that’s useful for a given task and forgets the rest."
Read more in the Facebook AI Blog (ai.facebook.com) and a dutiful Yannic Kilcher paper discussion (42 minutes on youtube.com).
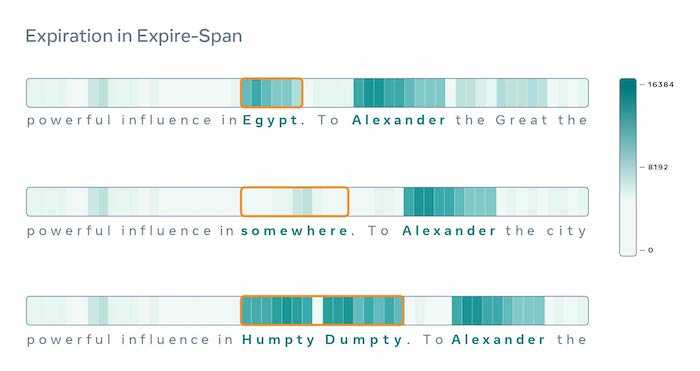
Facebook AI Research (FAIR)
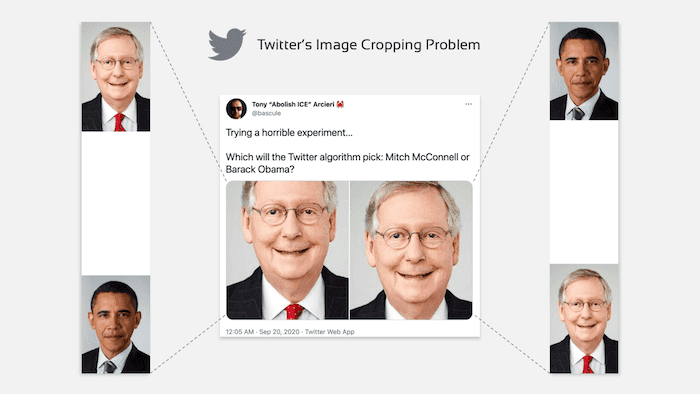
⚖️ Responsible AI – Last year, Twitter received heavy criticism over their image cropping algorithm, which often preferred white faces over black ones (theguardian.com reported). For example, in these tweets, US Senator Mitch McConnell's face is chosen over Barack Obama's face regardless of their positioning in the image. Now, the company has published a technical investigation as an academic paper (arXiv) and shared their learnings in an engineering blog post. To blame is a saliency algorithm trained on human eye-tracking data that Twitter now chose to disable in favor of full-size images and manual cropping. (blog.twitter.com)
👩💻 Code & Tools – Google published MoveNet, an "ultra fast and accurate" pose detection model on Tensorflow Hub, free to use. The model tracks 17 keypoints on the human body and is available in two versions: A smaller version called Lightning intended for latency-critical applications and Thunder designed for applications that require high accuracy. According to the announcement, both models run faster than real-time (30+ FPS) on most desktop and mobile devices. (blog.tensorflow.org)
📅 Event – CVPR, the Conference on Computer Vision and Pattern Recognition, is the most important Computer Vision Conference and will be held entirely virtual this year. Out of all CV conferences or journals, CVPR has the highest rank following the h5 index. Find the conference program for June 19 – 25th here: cvpr2021.thecvf.com (no HTTPS).











