The handling of the goods in a high rack by a shelf control unit (RBG) can be formulated as a reinforcement learning problem. The aim of the prototype in this article is to explain the basic functioning of a shelving unit. Based on these basics, more complex scenarios can be mapped to find more efficient strategies for existing or future high-bay warehouses.
Getting started with Reinforcement Learning
Reinforcement Learning is based on the principle of an agent's interaction (Agent) with an environment (Environment) . The agent can use action (Action) interact with the environment and thus influence it. The state of the environment is calculated in the form of an observation (Observation) perceived by the agent. This creates a change between action and observation. In addition to the observation, the agent contains a reward (Reward) after each action. The goal of Reinforcement Learning is to maximize the reward an agent receives. During training, the agent's behavior is gradually adjusted to earn higher rewards.
 State Action Graph
State Action Graph
Operating a high rack as a reinforcement learning problem
Environment/Environment - Condition of high rack, shelf and demand
For the prototype, the shelf and the demand are displayed as easily as possible. In particular, the demand can be formulated individually in complex ways, depending on the nature of the process in which the high rack is embedded.
- The high rack is defined as rectangular with $w*h' seats. A place can contain an item or be empty.
- A place in the warehouse is defined as a put-away point. New goods appear there when the space is empty.
- Goods are stored in the outsourcing point to remove them from the shelf. The items in the demand list are processed using the swap point.
- The current demand for goods is given as a list of items. (An alternative would be, for example.B a queue with an exact order)
- The position of the shelf control unit is represented by xy coordinates.
- The RBG can be empty or carry an item.
Observation/Observation
The state of the high-bay warehouse described above must be encoded in the form of an observation in order to be able to serve as input for the algorithm. There are several ways to do this. A simple variant is to write each relevant variable into a list and use the complete list as a one-dimensional input. The two-dimensional structure of the shelf would be reshaped.
However, an encoding variant that retains the spatial structure may be more useful because it can use techniques that use spatial structures such as.B convolution meshes. Such a representation retains the two-dimensional arrangement of the shelf. In the third dimension (depth or 'channels'/'channels') information can be encoded, such as .B item type, RBG position, item requirement, etc.
 Example coding of a shelf with two item types. Channel in this graphic refers to the encoding of the information ('channel'), not to a channel of a channel shelf.
Example coding of a shelf with two item types. Channel in this graphic refers to the encoding of the information ('channel'), not to a channel of a channel shelf.
Action room - Shelf control unit
- To change the position, the device can move up, down left, and right.
- To interact with the shelf, the shelving machine can pick up and store goods.
- If there is no need for action, the device can wait.
Reward/Reward
The formulation of the reward is crucial for the learning success and meaningfulness of the agent's behavior. Frequent small rewards can help the learning process and thus speed it up - but also implicit behavior and must therefore be chosen wisely. The main reward in this scenario is to store goods for the need. Further auxiliary rewards such as.B for the removal of goods from the storage point and movement of correct goods to the delivery point can support the learning process. Negative rewards at each time step create an urgency in the agent's action.
Scenario
An example scenario is created to check whether the trained agent chooses meaningful actions.

- Shelf size: height 4, width 4
- There are three different product types ('1', '2' and '3')
- Probability of a need (per environmental step): 10%
- Probability of new goods appearing in put-away area: 50%
- The probabilities that demand and replenishment of the product type 1.2 or 3 arise depends on the stock of the warehouse. The more frequently an item is in stock, the less likely it is to replenish.
- Maximum number of concurrent requirements: 1
Baseline
To compare the learned agent, a rules-based method is considered a baseline. The basic principle is to place items from the put-away space on a free space with the smallest distance to the put-away space. If there is demand on the shelf, the required item is brought to the removal site with the smallest distance to the RBG. Thus, the shortest possible distances should be preferred.
Pseudocode of the Baseline Policy:
# if payload is not empty
# if payload is demand
# goto target and drop
# else (payload is not demand)
# if rack is full
# go to target and drop (free up new space if there is demand, rack is full and only non-demand items in rack)
# else
# goto closest empty slot and drop
# else (payload is empty)
# if demand in rack
# go to demand in rack and pick up
# else (demand not in rack)
# if at source
# pick
# if empty slots left
# go to source
# else (no empty slots left)
# if all demand slots are full
# if no demand in rack
# go to source (go to source to free spawn space for demanded item)
# else (not all demand slots full)
# go to target (for quick delivery at next demand)Result
This section shows various snippets of a trained agent's behavior.
| Supplies |
|---|
 |
| Replenishment is recognized as such and taken out of the storage point to store it. |
| Store |
|---|
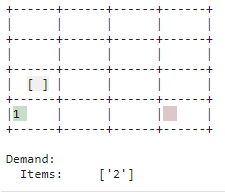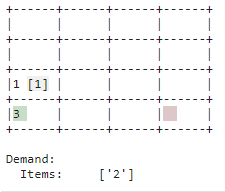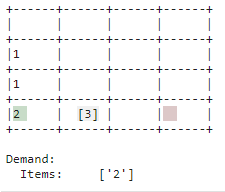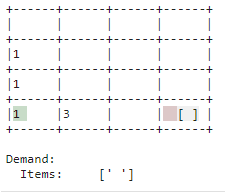 |
| Replenishment that is not immediately needed is stored. The bin is used as such. This creates space in the put-away point for new replenishment and allows you to respond more quickly to demand when the corresponding item is in stock. |
| Need |
|---|
| The demand is associated with correct items in the warehouse and complied with by placing the item in the outsourcing area. |
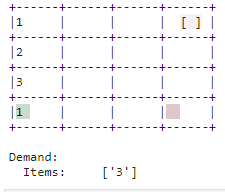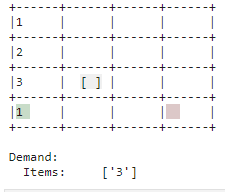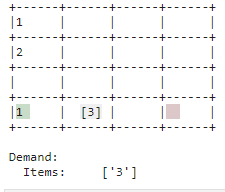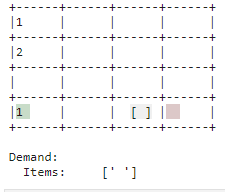 |
| Filling |
|---|
| The bearing is filled from the bottom left, so short distances (to the storage point) are preferred. |
 |
Throughput
 The figure shows the throughput of each of the RL agent and the baseline over 1000 time steps (300 repetitions each, saturated over 100 samples, 95% confidence interval).
Up to approx. time step 600, the RL agent is on average better than the baseline, then the baseline.
Already in this simple scenario, strategies can be discovered in a short time that are a competitive alternative to a strong baseline. Further optimizations can be used to further expand the existing approaches. In more complex scenarios, there is more scope for advanced strategies, which in turn provides opportunities for the RL agent.
The figure shows the throughput of each of the RL agent and the baseline over 1000 time steps (300 repetitions each, saturated over 100 samples, 95% confidence interval).
Up to approx. time step 600, the RL agent is on average better than the baseline, then the baseline.
Already in this simple scenario, strategies can be discovered in a short time that are a competitive alternative to a strong baseline. Further optimizations can be used to further expand the existing approaches. In more complex scenarios, there is more scope for advanced strategies, which in turn provides opportunities for the RL agent.
Learnings
There are a number of things to keep in mind when creating an environment for reinforcement learning. For example:
- Analyzing the behavior of trained agents helps identify any errors in the design of rewards. Such errors manifest themselves, for example, in the repetition of a sequence of supposedly useless actions.
- If possible, it makes sense to create a baseline policy to rank the quality of the agent.
- Designing a scalable world (size and difficulty) helps you quickly debug various RL algorithms.
- Understanding the parameters of the algorithm and its effects is important in order to be able to counteract errors in a targeted manner.
- A hyperparameter search can help to find robust parameters.
Conclusion and outlook
Creating the control of an shelf control unit is a challenging task. This article shows that Reinforcement Learning can be used to learn how to control an shelf control unit. The learned behavior could be used for control, or help identify better movement and occupancy strategies for a given scenario. The throughput achieved is competitive with a rule-based approach.
A more robust, practice-oriented approach could be instead of learning the complete control, choosing or switching between established strategies given the demand and storage conditions in order to be able to react flexibly.





