



TL;DR
- The bottleneck in AI-powered software development is shifting from writing code to alignment: the mutual understanding between humans and AI.
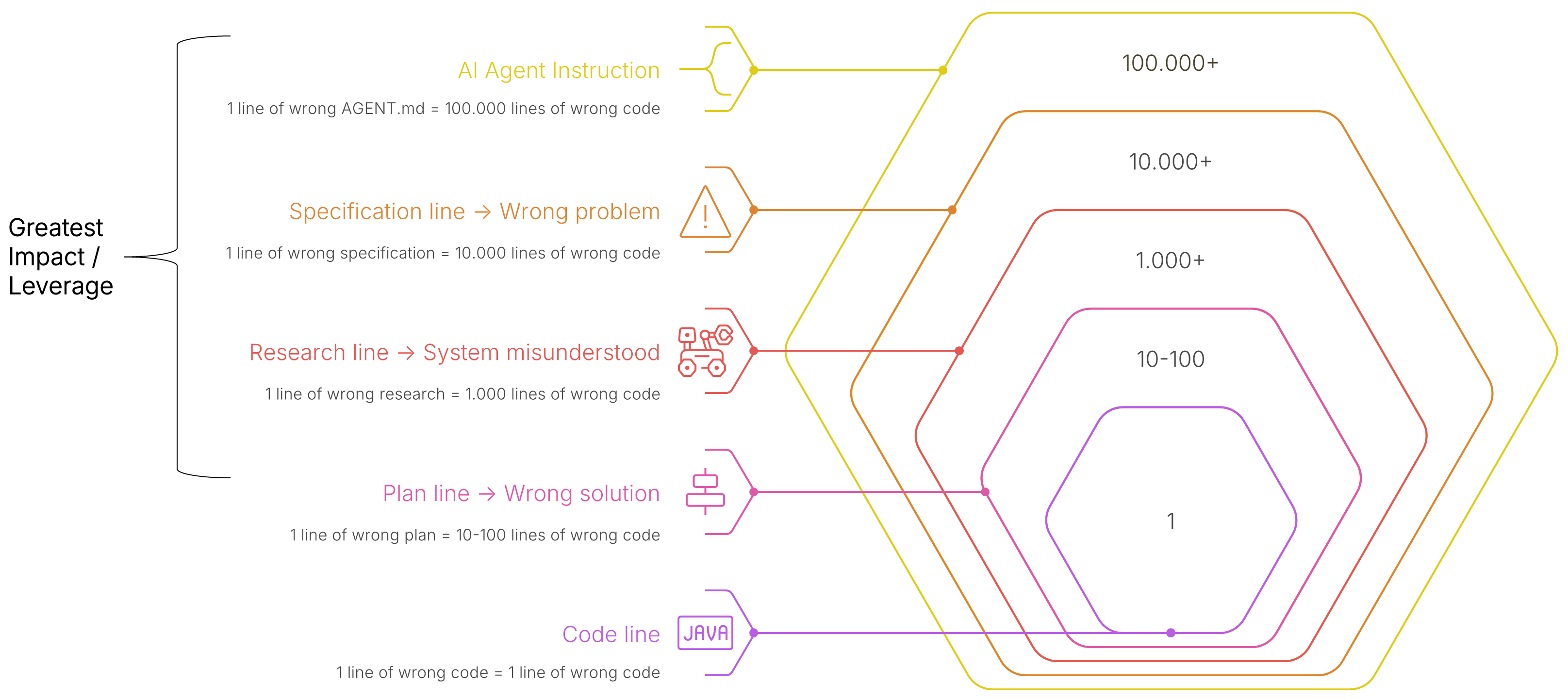
- Errors in specifications multiply by a factor of 10,000 in the generated code. The leverage is no longer at the code level, but in the quality of specs and plans.
- Spec-Anchored frameworks like OpenSpec continuously maintain specifications and are also suitable for brownfield projects. This is the approach that is currently proving most effective in our client projects.
The new bottleneck isn't code
Anyone who productively uses Cursor, GitHub Copilot, or Claude Code today quickly realizes: The real problem is rarely that the AI doesn't produce code. The problem is that it produces the wrong code. Not because the model is bad, but because the input wasn't precise enough.
In our client projects, we've been observing the same effect for months. Teams that previously struggled with implementation speed are now struggling with alignment. The question is no longer "How fast can we build this?", but "Does the AI truly understand what we mean?"
It's a structural problem that can be solved systematically. The approach is called Spec-Driven Development.
Errors compound
An error in the code affects one line. That's quickly corrected; the AI often finds it itself in the next iteration.
An error in the plan generates dozens of lines of incorrect code. The agent diligently executes the plan but heads in the completely wrong direction. The review becomes time-consuming because one first has to understand where the deviation originated.
An error in the specification leads to thousands of lines of unusable code. Entire components are created that no one needs or that interact incorrectly with each other.
An error in the agent instructions is the worst case. Instructions are read during every session. An incorrect standard is permanently carried into every new implementation. We have experienced this with clients in practice: A faulty directive in a central instruction file produced inconsistent code.
Therefore, anyone looking for the greatest leverage for code quality must absolutely start with specifications and agent instructions.
AI is the new senior developer on day one
Many teams struggle with this paradigm shift: they continue to treat AI as merely a tool, rather than a new senior developer on their first day.
This developer is technically strong. But they don't know the architecture. They know nothing about the company domain, internal conventions, preferred patterns, or the rationale behind specific design decisions. Without this knowledge, they produce code that, while functional, doesn't fit into the system.
The solution is the same as with real onboarding: structured access to documentation, specs, API guidelines, security requirements, and deployment processes. The difference is that this onboarding happens once, and these requirements don't need to be provided with every new prompt. This is where Progressive Disclosure becomes relevant.
Progressive Disclosure means not always providing the entire context (that overloads the context window and degrades results), but enabling the AI to retrieve the relevant context itself when needed. In practice, we implement this using hierarchical skill files. The AI navigates a tree structure to find the relevant information. Main rule: Keep the top level as small as possible and offload detailed knowledge into sub-files.
Three Maturity Levels for Spec-Driven Development
Not every team needs to go all-in immediately. We distinguish three maturity levels:
Spec First: The Specification as a Starting Point
Frameworks like Spec-Kit or the BMAD Method use a specification as a starting point for AI implementation. You write the spec, hand it over to the agent, and it implements it. This is already significantly better than pure prompt engineering, but it has a weakness: after implementation, the spec doesn't live on. For the next change, the reference point is missing.
Spec Anchored: The Specification Lives On
This is the maturity level we currently recommend for client projects. OpenSpec is the framework we've had the best experience with here. The key difference: The specification is not just used as a starting point, but is continuously maintained.
In practice, this means:
- Delta Specs only describe changes and do not redefine the entire system.
- After implementation, the delta spec is archived into the central overall specification archived.
- Old specs remain consistent because they are reconciled against the current state.
- This also works for Brownfield projects, where an existing codebase is already present.
The strategic value of a well-maintained spec extends beyond the current project. A technology-independent specification can theoretically be transferred to a completely different tech stack. In legacy migration projects, we use precisely this approach: old code becomes a spec, the spec is migrated, and the new implementation emerges from the migrated spec.
Spec as Source: The future, but not yet production-ready
Here, the spec serves as the single source of truth, from which the code is fully generated. This is conceptually compelling, but for productive projects, it is currently still a pipe dream.
The workflow in practice
A typical spec-driven workflow in our projects looks like this:
- Create Specification - Requirements clarification in dialogue with the AI. The AI asks clarifying questions instead of making assumptions (this must be explicitly instructed).
- Design and Plan - Architecture draft, schema definition, task breakdown. This is where the actual review takes place, not just during coding.
- Implementation by AI Agents - Using tests and reflection loops. We employ a simple loop: the agent implements, an external check (linting, tests, compilation) is performed, and if an error occurs, it returns to the beginning.
- Verification - Comparing the generated code against the specification.
- Archiving - The implemented spec is integrated into the central overall specification.
Our experience shows: If the plan is sound, the implementation is viable in 90% of cases. The review effort shifts entirely from code review to plan review. This also changes how teams collaborate.
How Teams Change
Ticket Slicing Works Differently
We have observed an interesting pattern in several projects: tickets optimally sliced for human developers (small, atomic, clearly delimited) sometimes perform suboptimally for AI agents. The reason is that AI often implements related functionality without being explicitly asked. A ticket like "Add validation for field X" might lead the agent to also validate fields Y and Z, as this seems logical within the context.
Therefore, tickets need to be re-scoped for AI workflows. Neither overly large nor overly small tickets, but rather cohesive work packages, perform best.
Roles Shift
The traditional separation into Requirements Engineer, Software Engineer, and Test Engineer creates a disproportionately high coordination overhead in AI-assisted development. In our most efficient setups, Requirements Engineers prepare very detailed specifications (e.g., specs in Markdown, structured proposals), while Software and Test Engineering converge or are even handled by the same agent.
Git as a Collaboration Model
For multi-developer scenarios, a Git-based model has proven effective. Requirements Engineers create change proposals as branches. Implementers select changes from their queue and process them in parallel Git Worktrees. This allows multiple agents to work on the same codebase simultaneously without causing conflicts.
Remaining Risks
Spec-Driven Development doesn't solve all problems. Performance-sensitive architectural design still requires human judgment. When legal requirements mandate millisecond-range response times, no specification alone will suffice.
What works excellently, however, is using AI for iterative performance tuning. In a customer project, we implemented a self-improvement loop where the agent conducts load tests, analyzes results, proposes configuration changes, and re-tests. For fine-tuning cluster configurations or database indexes, this is far more effective than manual trial-and-error.
The topic of agent security also remains relevant. Agents with overly broad permissions can cause damage. Our strategy includes fine-grained API tokens, isolated sandbox environments for testing, and the principle "agents may prepare, but not execute without approval."
Spec-Driven in Legacy Projects
A particularly effective application is legacy migration. The classic approach of directly translating old code into new code regularly fails due to the complexity of evolved systems. Spec-Driven reverses the process:
- Discovery - Agents analyze the legacy codebase and identify dependencies.
- Spec Generation - A technology-independent specification is extracted from the existing code.
- Verification - The spec is verified against the runtime behavior of the old system.
- Spec Migration - The spec is adapted to the target architecture.
- Re-implementation - The target code is generated from the migrated spec.
We are currently applying this in migration projects , including COBOL-to-Java and Struts-to-Angular migrations. The advantage over direct code translation: The spec, acting as an intermediate layer, captures the conceptual differences between the old and new systems instead of hiding them in the code.
The biggest leverage is not in the tooling
Tools are getting better every month. Cursor, Claude Code, GitHub Copilot – they are all moving towards agent-based workflows. But even the best tooling is of little help if the input is poor.
Those investing today should focus on three areas: the quality of specifications, context management (how AI finds relevant information), and change management within the team, as roles and workflows are currently undergoing fundamental shifts.
This is less glamorous than a new tool announcement. However, it's the difference between teams that become more productive with AI and teams that merely produce the same output faster, but with lower quality.
If you are currently introducing AI-powered development in your team, or if existing approaches are not delivering the expected results, talk to us. We are happy to share our experiences from the past few months.
FAQ: Spec-Driven Development
What is Spec-Driven Development (SDD) in the context of AI?
Spec-Driven Development is an approach in AI-powered software development where precise, well-maintained specifications (specs) serve as the central control and knowledge source for AI agents. Instead of merely providing vague prompts to the AI, detailed requirements and plans are developed from which the AI generates the code. This drastically minimizes errors and improves alignment between humans and machines.
Why isn't traditional prompt engineering sufficient?
Classic prompt engineering works well for isolated, small code snippets. However, for complex systems, AI lacks overarching domain knowledge and architectural understanding. This leads to an error multiplier effect: imprecise prompts generate thousands of lines of unusable code. Spec-Driven Development solves this problem through structured context transfer (Progressive Disclosure).
What is the difference between Spec-First and Spec-Anchored?
In "Spec-First," a specification is written once and used for code generation, but then often neglected ("orphaned"). "Spec-Anchored" frameworks (e.g., OpenSpec) use the specification continuously. Changes are planned as "Delta-Specs," implemented, and then archived into the overall specification. This keeps the documentation consistent and up-to-date.
How does Spec-Driven Development help with legacy migrations?
When modernizing legacy systems (such as COBOL to Java), direct code-to-code translation often fails. In the Spec-Driven approach, AI agents analyze the legacy code and extract a technology-agnostic specification from it. This extracted spec then serves as a blueprint to generate the new, modern target code.
Which tools support Spec-Driven Workflows?
This concept can be implemented with modern AI development environments like Cursor, GitHub Copilot, or Claude Code. However, the key is not just the IDE, but the framework for specification management. OpenSpec or the BMAD framework offer structured approaches for this purpose, to guide agents safely and efficiently.










