



TL;DR
- Der Engpass in der KI-gestützten Softwareentwicklung verschiebt sich vom Codeschreiben zum Alignment: dem gegenseitigen Verständnis zwischen Mensch und KI.
- Fehler in der Spezifikation multiplizieren sich um Faktor 10.000 im generierten Code. Der Hebel liegt nicht mehr auf Code-Ebene, sondern bei der Qualität von Specs und Plänen.
- Spec-Anchored-Frameworks wie OpenSpec pflegen Spezifikationen kontinuierlich weiter und eignen sich auch für Brownfield-Projekte. Das ist der Ansatz, der sich in unseren Kundenprojekten aktuell am besten bewährt.
Der neue Engpass heißt nicht Code
Wer heute Cursor, GitHub Copilot oder Claude Code produktiv nutzt, merkt schnell: Das eigentliche Problem ist selten, dass die KI keinen Code produziert. Das Problem ist, dass sie den falschen Code produziert. Nicht weil das Modell schlecht wäre, sondern weil der Input nicht präzise genug war.
In unseren Kundenprojekten beobachten wir seit Monaten denselben Effekt. Teams, die vorher mit Implementierungsgeschwindigkeit kämpften, kämpfen jetzt mit Alignment. Die Frage ist nicht mehr "Wie schnell können wir das bauen?", sondern "Versteht die KI wirklich, was wir meinen?"
Es ist ein strukturelles Problem, das sich systematisch lösen lässt. Der Ansatz heißt Spec-Driven Development.
Fehler multiplizieren sich nach oben
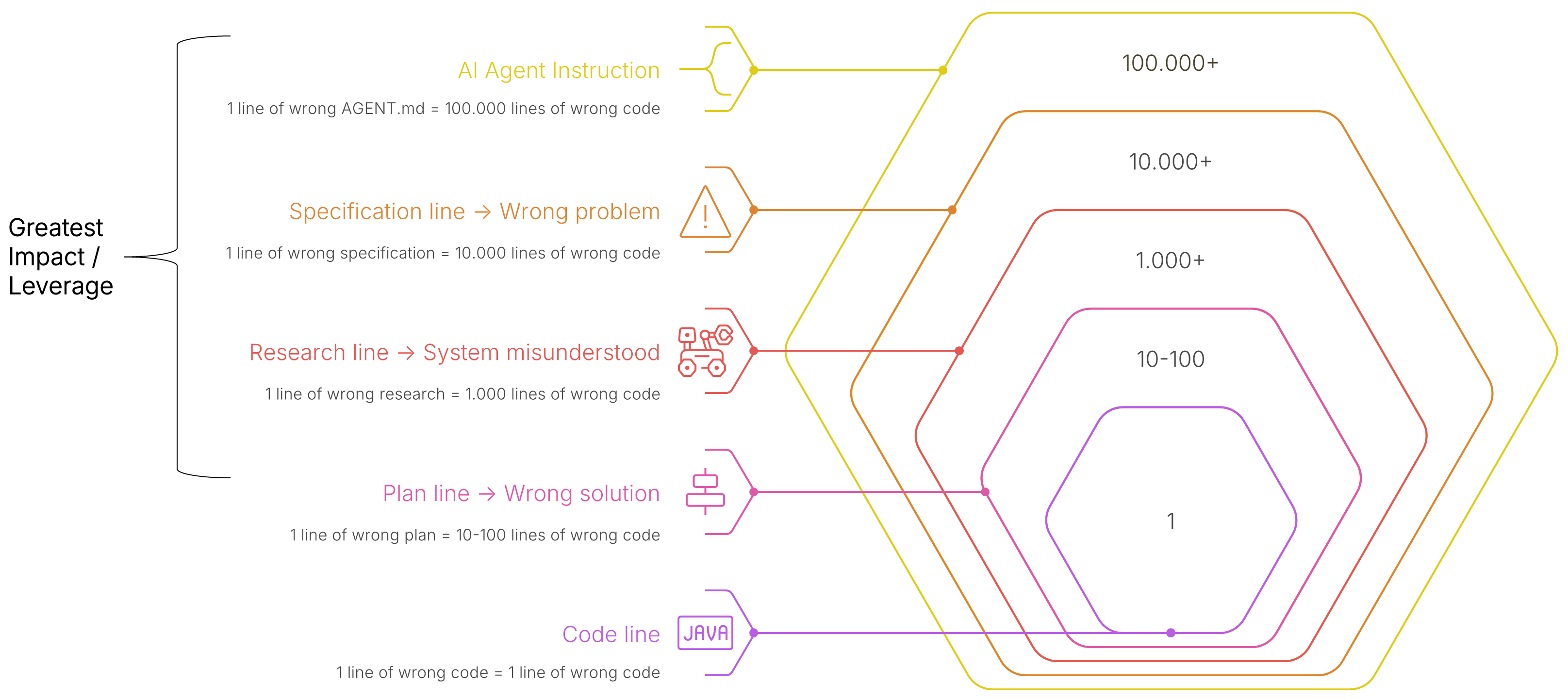
Ein Fehler im Code betrifft eine Zeile. Das ist schnell korrigiert, die KI selbst findet ihn oft beim nächsten Durchlauf.
Ein Fehler im Plan erzeugt Dutzende Zeilen falschen Code. Der Agent setzt den Plan zwar gewissenhaft um, läuft dabei aber in die völlig falsche Richtung. Das Review wird aufwendig, weil man erst verstehen muss, wo die Abweichung ihren Ursprung hat.
Ein Fehler in der Spezifikation führt zu tausenden Zeilen unbrauchbarem Code. Es entstehen ganze Komponenten, die niemand braucht oder die falsch miteinander interagieren.
Ein Fehler in den Agenten-Instruktionen ist der schlimmste Fall. Instruktionen werden bei jeder Session gelesen. Ein falscher Standard wird dauerhaft in jede neue Implementierung getragen. Wir haben das bei Kunden in der Praxis erlebt: Eine fehlerhafte Vorgabe in einer zentralen Instruktionsdatei hat inkonsistenten Code produziert.
Wer also den größten Hebel für die Code-Qualität sucht, muss zwingend bei den Spezifikationen und Agenten-Instruktionen ansetzen.
KI ist der neue Senior-Entwickler am ersten Tag
Vielen Teams fällt dieser Paradigmenwechsel schwer: Sie behandeln KI weiterhin als reines Tool und nicht wie einen neuen Senior-Entwickler an seinem ersten Arbeitstag.
Dieser Entwickler ist fachlich stark. Aber er kennt die Architektur nicht. Er weiß nichts über die Unternehmensdomäne, interne Konventionen, bevorzugte Patterns oder die Hintergründe bestimmter Design-Entscheidungen. Ohne dieses Wissen produziert er Code, der zwar funktioniert, aber nicht ins System passt.
Die Lösung ist dieselbe wie beim echten Onboarding: strukturierter Zugang zu Dokumentation, Specs, API-Guidelines, Security-Vorgaben und Deployment-Prozessen. Der Unterschied ist, dass dieses Onboarding einmal stattfindet und diese Vorgaben nicht bei jedem neuen Prompt mitgegeben werden müssen. Hier wird Progressive Disclosure relevant.
Progressive Disclosure bedeutet, nicht den gesamten Kontext immer mitzugeben (das überlastet das Context Window und verschlechtert die Ergebnisse), sondern der KI zu ermöglichen, bei Bedarf den relevanten Kontext selbst abzurufen. In der Praxis setzen wir das über hierarchische Skill-Dateien um. Die KI navigiert entlang einer Baumstruktur zur jeweils relevanten Information. Hauptregel: Die oberste Ebene möglichst klein halten und Detailwissen in Unterdateien auslagern.
Drei Reifegrade für Spec-Driven Development
Nicht jedes Team muss sofort das volle Programm fahren. Wir unterscheiden drei Reifegrade:
Spec First: Die Spezifikation als Startpunkt
Frameworks wie Spec-Kit oder die BMAD Method nutzen eine Spezifikation als Ausgangspunkt für die KI-Implementierung. Man schreibt die Spec, übergibt sie an den Agenten, und der implementiert. Das ist bereits deutlich besser als reines Prompt-Engineering, hat aber eine Schwäche: Nach der Implementierung lebt die Spec nicht weiter. Bei der nächsten Änderung fehlt der Bezugspunkt.
Spec Anchored: Die Spezifikation lebt weiter
Das ist der Reifegrad, den wir aktuell in Kundenprojekten empfehlen. OpenSpec ist hier das Framework, mit dem wir die besten Erfahrungen gemacht haben. Der zentrale Unterschied: Die Spezifikation wird nicht nur als Start verwendet, sondern kontinuierlich gepflegt.
In der Praxis heißt das:
- Delta-Specs beschreiben nur Änderungen und nicht das gesamte System neu.
- Nach der Implementierung wird die Delta-Spec in die zentrale Gesamtspezifikation archiviert.
- Alte Specs bleiben konsistent, weil sie gegen den aktuellen Stand abgeglichen werden.
- Das funktioniert auch für Brownfield-Projekte, bei denen bereits eine existierende Codebase vorliegt.
Der strategische Wert einer gut gepflegten Spec geht über das aktuelle Projekt hinaus. Eine technologieunabhängige Spezifikation lässt sich theoretisch in einen komplett anderen Tech-Stack überführen. In Legacy-Migrationsprojekten nutzen wir genau diesen Ansatz: Alt-Code wird zu Spec, die Spec wird migriert, und die neue Implementierung entsteht aus der migrierten Spec.
Spec as Source: Die Zukunft, aber noch nicht produktionsreif
Hier dient die Spec als einzige Quelle der Wahrheit, aus der der Code vollständig generiert wird. Das ist konzeptionell überzeugend, für produktive Projekte aktuell aber noch Zukunftsmusik.
Der Workflow in der Praxis
Ein typischer Spec-Driven-Workflow sieht in unseren Projekten so aus:
- Spezifikation erstellen - Requirements-Klärung im Dialog mit der KI. Die KI stellt Rückfragen, statt Annahmen zu treffen (das muss explizit instruiert werden).
- Design und Plan - Architektur-Draft, Schema-Definition, Task-Zerlegung. Hier findet das eigentliche Review statt und nicht erst beim Code.
- Implementierung durch KI-Agenten - Mit Tests und Reflexionsschleifen. Wir nutzen einen einfachen Loop: Agent implementiert, externer Check (Linting, Tests, Compilation), bei Fehler zurück zum Start.
- Verification - Abgleich des generierten Codes gegen die Spezifikation.
- Archivierung - Die implementierte Spec wird in die zentrale Gesamtspezifikation überführt.
Unsere Erfahrung zeigt: Wenn der Plan stimmt, ist die Implementierung in 90% der Fälle brauchbar. Der Review-Aufwand verlagert sich komplett vom Code-Review zum Plan-Review. Das verändert auch, wie Teams zusammenarbeiten.
Was sich für Teams ändert
Ticket-Schnitte funktionieren anders
Wir haben in mehreren Projekten ein interessantes Muster beobachtet: Tickets, die für menschliche Entwickler optimal geschnitten sind (klein, atomar, klar abgegrenzt), funktionieren für KI-Agenten manchmal suboptimal. Der Grund liegt darin, dass KI verwandte Funktionalität oft ungefragt mit implementiert. Ein Ticket "Füge Validierung für Feld X hinzu" führt dazu, dass der Agent auch die Felder Y und Z validiert, weil das aus dem Kontext logisch erscheint.
Tickets müssen daher für KI-Workflows neu geschnitten werden. Weder zu große noch zu kleine Tickets, sondern zusammenhängende Arbeitspakete funktionieren am besten.
Rollen verschieben sich
Die klassische Trennung in Requirements Engineer, Software Engineer und Test Engineer erzeugt bei KI-gestützter Entwicklung unverhältnismäßig viel Abstimmungsaufwand. In unseren effizientesten Setups bereiten Requirements Engineers sehr detailliert vor (Specs in Markdown, strukturierte Proposals), während Software- und Test-Engineering näher zusammenrücken oder sogar vom selben Agenten übernommen werden.
Git als Kollaborationsmodell
Für Multi-Entwickler-Szenarien hat sich ein Git-basiertes Modell bewährt. Requirements Engineers erstellen Change-Proposals als Branches. Implementierer wählen Changes aus ihrer Queue und bearbeiten sie in parallelen Git Worktrees. Das ermöglicht es mehreren Agenten, gleichzeitig an derselben Codebase zu arbeiten, ohne Konflikte zu verursachen.
Risiken, die bleiben
Spec-Driven Development löst nicht alle Probleme. Performance-sensitives Architekturdesign erfordert weiterhin menschliches Urteilsvermögen. Wenn gesetzliche Vorgaben Antwortzeiten im Millisekundenbereich vorschreiben, reicht keine Spec allein.
Was allerdings hervorragend funktioniert, ist der Einsatz der KI für iteratives Performance-Tuning. In einem Kundenprojekt haben wir einen Self-Improvement-Loop aufgesetzt, bei dem der Agent Lasttests durchführt, Ergebnisse analysiert, Konfigurationsänderungen vorschlägt und erneut testet. Für das Feintuning von Cluster-Konfigurationen oder Datenbankindizes ist das weitaus effektiver als manuelles Trial-and-Error.
Auch das Thema Agent-Sicherheit bleibt relevant. Agenten mit zu breiten Berechtigungen können Schaden anrichten. Unsere Strategie umfasst feingranulare API-Tokens, isolierte Sandbox-Umgebungen für Tests und das Prinzip "Agenten dürfen vorbereiten, aber nicht ohne Freigabe ausführen".
Spec-Driven in Legacy-Projekten
Ein besonders wirkungsvoller Einsatz ist die Legacy-Migration. Der klassische Ansatz, Alt-Code direkt in neuen Code zu übersetzen, scheitert regelmäßig an der Komplexität gewachsener Systeme. Spec-Driven dreht den Prozess um:
- Discovery - Agenten analysieren die Legacy-Codebase und identifizieren Abhängigkeiten.
- Spec-Generierung - Aus dem bestehenden Code wird eine technologieunabhängige Spezifikation extrahiert.
- Verifikation - Die Spec wird gegen das Laufzeitverhalten des Altsystems geprüft.
- Migration der Spec - Die Spec wird auf die Zielarchitektur angepasst.
- Neuimplementierung - Der Zielcode entsteht aus der migrierten Spec.
Wir setzen das aktuell in Migrationsprojekten ein, unter anderem bei COBOL-zu-Java- und Struts-zu-Angular-Migrationen. Der Vorteil gegenüber direkter Code-Übersetzung: Die Spec als Zwischenschicht fängt die konzeptionellen Unterschiede zwischen Alt- und Neusystem auf, statt sie im Code zu verstecken.
Der größte Hebel liegt nicht im Tooling
Die Tools werden jeden Monat besser. Cursor, Claude Code, GitHub Copilot – sie alle bewegen sich in Richtung agentenbasierter Workflows. Aber das beste Tooling hilft wenig, wenn die Eingabe schlecht ist.
Wer heute investiert, sollte drei Bereiche fokussieren: die Qualität der Spezifikationen, das Kontextmanagement (wie die KI relevante Informationen findet) und das Change Management im Team, da sich Rollen und Arbeitsweisen gerade fundamental wandeln.
Das ist weniger glamourös als ein neues Tool-Announcement. Es ist aber der Unterschied zwischen Teams, die mit KI produktiver werden, und Teams, die nur schneller den gleichen Output in niedrigerer Qualität erzeugen.
Wenn Sie gerade dabei sind, KI-gestützte Entwicklung in Ihrem Team einzuführen, oder wenn bestehende Ansätze nicht die erhofften Ergebnisse liefern, sprechen Sie mit uns. Wir teilen gerne unsere Erfahrungen aus den letzten Monaten.
FAQ: Spec-Driven Development
Was ist Spec-Driven Development (SDD) im Kontext von KI?
Spec-Driven Development ist ein Ansatz in der KI-gestützten Softwareentwicklung, bei dem präzise, gepflegte Spezifikationen (Specs) als zentrale Steuerungs- und Wissensquelle für KI-Agenten dienen. Statt der KI nur vage Prompts zu geben, entwickelt man detaillierte Anforderungen und Pläne, aus denen die KI den Code generiert. Dies minimiert Fehler und verbessert das Alignment zwischen Mensch und Maschine drastisch.
Warum reicht herkömmliches Prompt-Engineering nicht aus?
Klassisches Prompt-Engineering funktioniert gut für isolierte, kleine Code-Snippets. Bei komplexen Systemen fehlt der KI jedoch das übergeordnete Domänenwissen und Architekturverständnis. Dies führt zu einem Fehler-Multiplikator-Effekt: Unpräzise Prompts generieren tausende Zeilen unbrauchbaren Code. Spec-Driven Development löst dieses Problem durch strukturierte Kontextübergabe (Progressive Disclosure).
Was ist der Unterschied zwischen Spec-First und Spec-Anchored?
Bei "Spec-First" wird eine Spezifikation einmalig geschrieben und zur Codegenerierung genutzt, danach aber oft vernachlässigt ("verwaist"). "Spec-Anchored" Frameworks (z. B. OpenSpec) nutzen die Spezifikation kontinuierlich. Änderungen werden als "Delta-Specs" geplant, implementiert und anschließend in die Gesamtspezifikation archiviert. Die Dokumentation bleibt so konsistent und aktuell.
Wie hilft Spec-Driven Development bei Legacy Migrationen?
Bei der Modernisierung von Altsystemen (wie COBOL zu Java) scheitert die direkte Code-zu-Code-Übersetzung oft. Im Spec-Driven Ansatz analysieren KI-Agenten den Legacy-Code und extrahieren daraus eine technologieunabhängige Spezifikation. Diese extrahierte Spec wird dann als Blaupause genutzt, um den neuen, modernen Zielcode zu generieren.
Welche Tools unterstützen Spec-Driven Workflows?
Das Konzept lässt sich mit modernen KI-Entwicklungsumgebungen wie Cursor, GitHub Copilot oder Claude Code umsetzen. Entscheidend ist jedoch nicht nur die IDE, sondern das Framework zur Spezifikationspflege. OpenSpec oder das BMAD-Framework bieten hierzu strukturierte Ansätze, um Agenten sicher und effizient anzuleiten.










